A Python to Rust Journey: Part 2 – The Rusty Way
Promises of "Significant" performance... delivered!
DEV DIARY
Allen Frasier
5/15/20246 min read
A Python to Rust Journey: Part 2 – The Rusty Way
Welcome to Part 2! In Part 1 of this blog series, I documented how I was challenged to improve a Python XML parser with another language. That language turned out to be Rust.
The TLDR:
Avg Start performance: 258 xml nests/sec
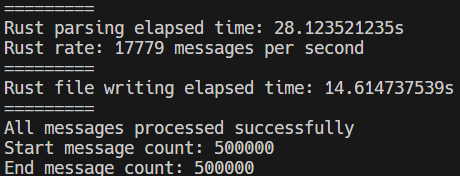
Avg End performance: 17,250 xml nests/sec
That’s a 64X improvement in processing performance!
The blog screen above shows even better results when my CPU's were hitting full burst speed, but this is not always the case
Rust is a true data devouring beast and so incredibly resource efficient while doing so
I will forever use Rust for heavy data processing, or until something better comes along!
Rust was not too difficult to learn, but... I did a lot of C programming in 2023 so it was not too big a jump
Rust forces you to rethink your OOP discipline – for the better.
Learning Rust
In February 2023, I started the Rust journey the usual way. The Rust book for starters and some practice code. The one thing that immediately struck me was the lack of OOP “rigor” in Rust and its community. This is not a Rust blog but I’ll point out these three things that really stood out:
Rust is great for data oriented design. You focus on your data objects and their immediate use.
Rust is more focused on composition over inheritance. Rust’s memory model kind of forces this. Object inheritance can get nasty in Rust, especially for beginners used to OOP.
No garbage collection! Can I say it again and shout it to the rooftops? NO GARBAGE COLLECTION!!! This was very evident in the difference in the amount of memory used by both parsers.
By mid-March, after a steady six weeks of tutorials in the deep cold of winter, I finally embarked on converting the Python parser as a spring rite. This took roughly three weeks as I decided to rewrite the Python parser from scratch with some new ideas I gained from the Rust practice.
All in all, Rust was easy to understand but a little more difficult to execute. The concepts of ownership, move, clone, copy and moo, er, cow that is... tripped up my initial code more often than I can count - thankfully the compiler and vs-code were very good at showing me where the problems were. Unlike with Python where you can just declare at your leisure, Rust is S.T.R.I.C.T. (hello "str" vs "String", I'm talking to you!) and will not work if your memory management or typing is not perfect, or near so. Well actually, it should just be darned perfect so one just has to get used to it - but it's all for the best.
Changes from Python
A major change from the Python parser was the treatment of the xml data. The Python parser used LXML (a performant C based XML module) to stream and parse the xml. While doing so, the streamer method would use LXML start and end event flags that captured entire xml nests. I took the nests and ran them through a custom module that parsed each financial data nest into a Python dataclass object. A second helper object that contained a specific sub-nest’s worth of data was also created. The main object basically held the contents of the xml and its real value was that it could be called upon to easily create any other data object that could be needed for ML, AI, and Data Science - namely json, csv and dataframes.
This object while useful, came at the cost of object construction and deconstruction overhead. With easily 500,000 financial data nests per 2GB XML file, and possibly hundreds of sub-objects per data nest, that’s a lot of memory churn within Python and its single GIL. When profiling performance, htop would show 1 cpu pegged at 100% and memory churning away as fast as it could with the overhead of garbage collection – thus the heart of my performance bottleneck in Python.
With Rust, I approached the problem not too differently but with two major distinctions:
The Rust streaming parsing uses a state machine to track where in the xml the parsing is happening.
Instead of creating a dataclass object, I use a Struct made of Vecs to hold each financial data nest. This is wicked fast and much easier on memory.
Rust Benefits
By not creating an empty Python dataclass and then filling it via parsing functions, I eliminated the object construction and eventual deconstruction overhead. In Rust, the state machine manages where in the nest the parser is and basically sips the needed data one line at a time into the Vecs that eventually populate the financial data nest Structs. This is so fast, it's basically crazy to watch in action. When the data is finally added to the Struct, Rust removes it from memory immediately. So in essence, I’m sipping data on a per line basis as fast as the cpu and memory can process it.
Instead of creating a nice OOP modular file structure, I wrote and compiled the Rust parser as a single main file binary. I originally thought about using PyO3 to integrate a Rust module that could be called by Python but that introduced a level of coupling that I was not comfortable with and frankly, it made unit-tests a bit harder to write as I would have to aggregate the logs from two different languages. Since I was using Apache Airflow as the pipeline orchestrator, calling the Rust binary was a simple BashOperator task, completely uncoupled from anything preceding it.
The greatest benefit of a single Rust binary was that everything needed to do the parsing was already compiled. Bye bye language interpreter overhead! The Rust binary definitely won the single-threaded race with its closer to the metal machine code available from the get-go. Additionally, the Rust compiler does a good job of profiling and managing the memory needs of the parser. This was clearly visible at the end of some test parsing runs. The amount of memory used by Rust to parse the same 500k nest xml file was considerably lower than Python. (See bullets in the next section)
Conclusion
Rust’s memory efficiency, pre-compiling, out of the box speed and the change to a state machine to manage data collections all combined to give me on average ...17,250 xml nests per second. That’s right. That’s over seventeen thousand per second! On the same server and memory configuration! Bye bye Docker and Kubernetes, no horizontal sailing, er scaling needed now! To put this in perspective, some numbers:
~28 seconds to process 500,000 financial data nests with the Rust parser (the screenshot for this post)
~32 minutes to process 500,000 financial data nests with the Python parser (the screenshot for part 1)
Python max memory usage: 23GB (base OS memory usage: 1.5GB)
Rust max memory usage: 7.5GB (base OS memory usage: 1.5GB)
Extend this to ~5mm data nests in a typical EDA cycle and we’re talking insane time savings.
This is essentially having data science EDA ready dataframes within 10 minutes instead of hours.
The statistics above were for only one specific and fairly wide dataframe. Additional dataframes can be created with the Rust parser with very little additional time and overhead. (Using the native Rust based Polars crate)
Well, I’m sold on Rust without any doubts now. For the dog days of summer, I have on my docket some experimentation with Rust multi-threading to see if I can squeeze even more out of the existing Rust parser.
Some people have asked me if switching the Python parser to replicate the state machine process of the Rust parser would improve the Python performance... that's a fair and very interesting question but one I don't think I'll be able to answer until I get a really large block of free time - if ever. My feeling is that with Rust, with fairly noob code that is not multi-threaded, I have a lot of head room to get better performance whereas with Python, the GIL will still be in the way unless I start looking at GIL sidestep tricks and Cython, etc... so I'd rather just stay in the Rust lane where everything is part of the base language. (I do believe a Python state machine would be faster than my existing parser - how much? Time will tell, if it allows.)
This was a fun blog to write and I touched on some great issues that deserve blogs on their own... stay tuned!
Hours
M-F 9:00-17:00 (CET)
